8 Factor Scores
Factor score estimation is a post-estimation step in SEM that involves deriving individual-level scores on latent variables from the fitted model. Ideally, any kind of inference should be made using the SEM instead on estimated individual-level scores because the estimation introduces estimation error. For example, if one is interested in the correlation of two latent factors, this correlation should be modeled and model-based estimates should be used for the inference. Common approaches include regression (or “Thurstone”) scoring, Bartlett scoring, and empirical Bayes methods, each trading-off bias and efficiency. Importantly, factor scores are not uniquely determined—they depend on the chosen estimation method and model specification—so they should be interpreted as approximations rather than exact measurements of the latent constructs. In applied work, factor scores are often used for secondary analyses, such as predicting outcomes or classifying individuals, but their uncertainty and potential indeterminacy should always be taken into account.
8.1 Factor-score estimation in Onyx
In Onyx, you can right-click on a fitted model view and choose “Estimation -> Obtain Latent / Missing Scores”. This creates a new dataset, which imputes all missing variables using a maximum-likelihood-based approach; this includes all latent variables, which are treated as completely missing (as they were not observed):
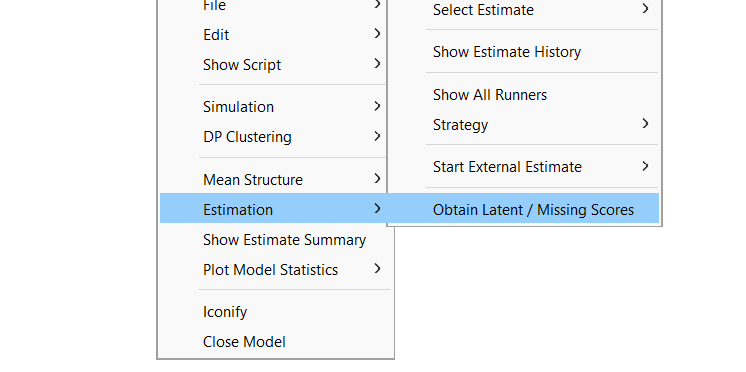
This new dataset can either be saved or be used to create plots.
The scores are computed as regression factor scores (also known as conditional mean scores). These are computed as expectation of a given missing value given the observed scores. This is also know as conditional mean imputation under a multivariate normal model.
8.2 Exercise
For the exercise, we will use the Holzinger Swineford dataset.
8.2.1 Holzinger Swineford
From the description provided in the lavaan package:
The classic Holzinger and Swineford (1939) dataset consists of mental ability test scores of seventh- and eighth-grade children from two different schools (Pasteur and Grant-White). In the original dataset (available in the MBESS package), there are scores for 26 tests. However, a smaller subset with 9 variables is more widely used in the literature (for example in Joreskog’s 1969 paper, which also uses the 145 subjects from the Grant-White school only).
The commonly used factor model for these 9 variables consists of three latent variables each measured by three indicators:
a visual factor measured by three variables: x1, x2 and x3
a textual factor measured by three variables: x4, x5 and x6
a speed factor measured by three variables: x7, x8 and x9
8.2.2 Tasks
Load the dataset
HolzingerSwineford1939.csvCreate a latent factor model with the first six observed variables (x1 to x6); allow a correlation of the two latent factors; name the model “VisualTextual”
Obtain factor scores of the two latent variables
Plot a scatter plot of the estimated factor scores from the visual and textual factor. What do you see? How does this relate to the latent correlation between the two factors?
Save the estimated data set to a file
9 Solution
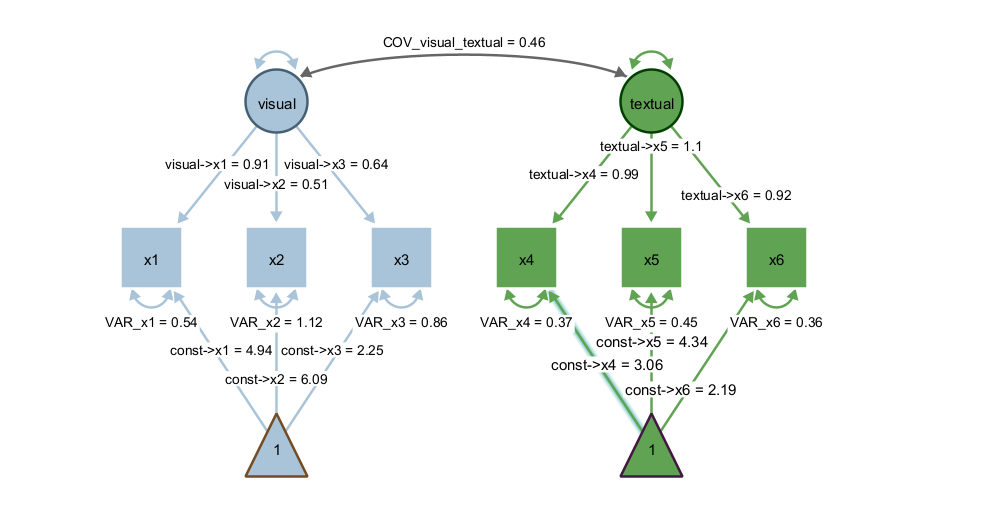
First, create the latent factor model. It should look like this:
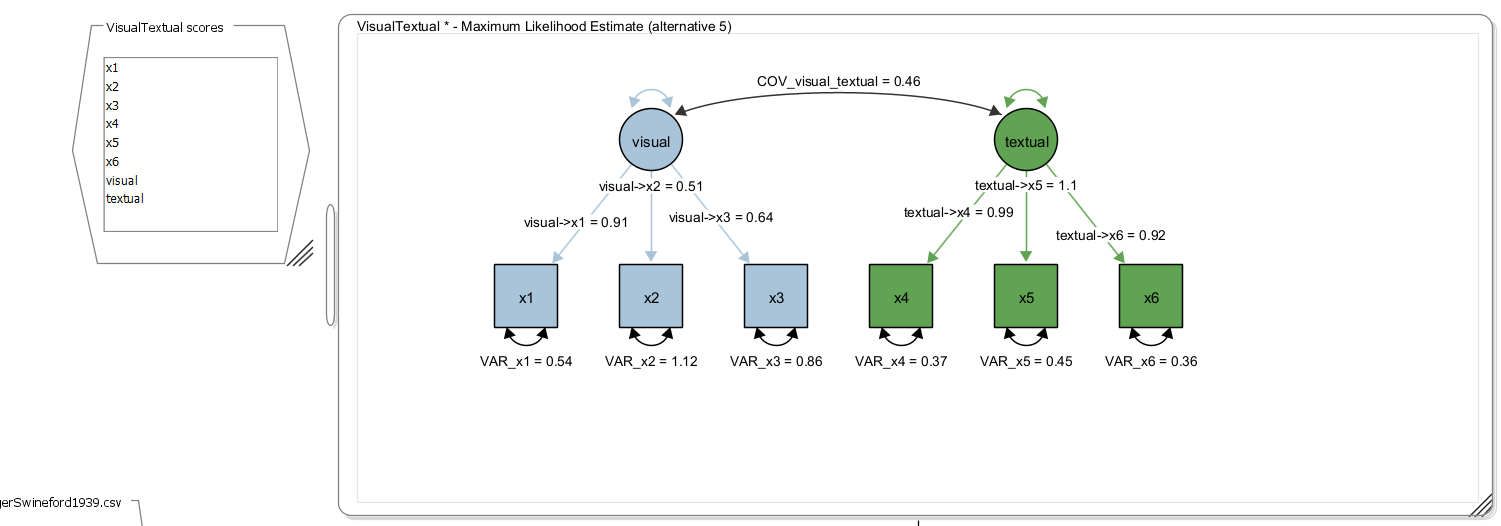
Next, obtain the factor score estimates – this opens a new dataset including the estimated scores as new variables; the names correspond to the names of the latent factors:
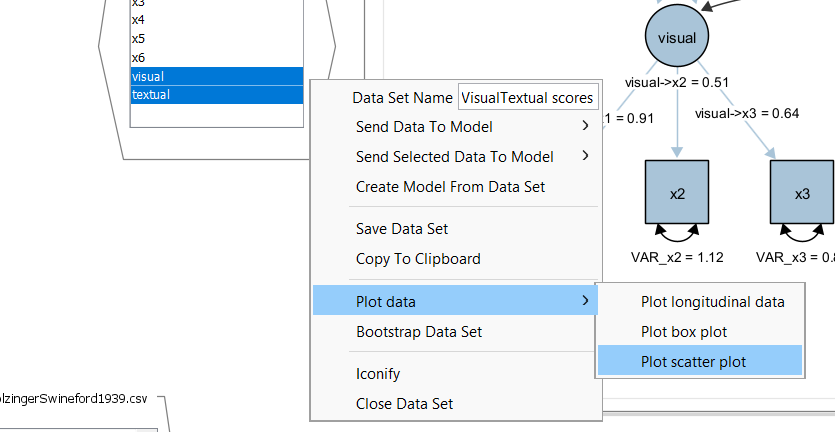
Then right-click on an empty space in the dataset view, select plot and then scatterplot:
This creates a scatterplot:
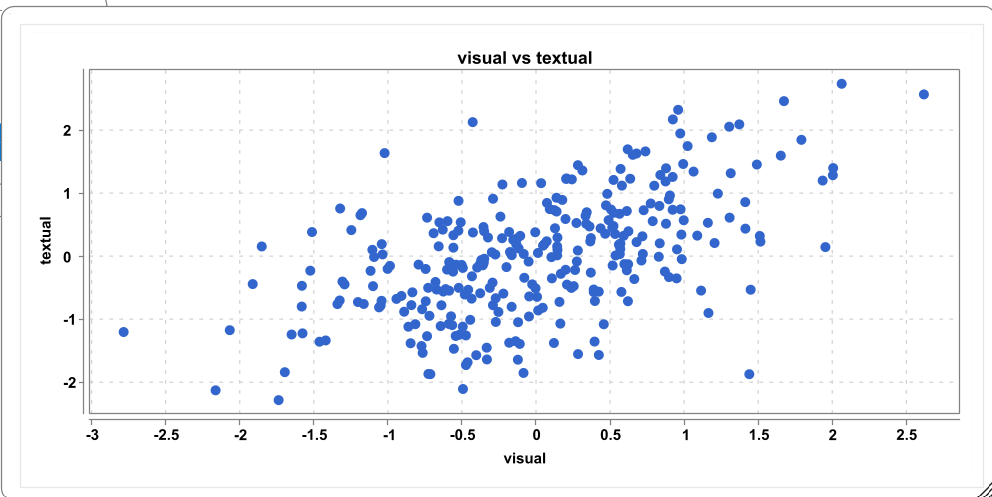
Here, we can see a positive correlation of medium size. This corresponds to the latent factor score correlation in the model. Note, however, that the model-based correlation is a better estimate (less biased and more precise) than estimating a correlation on the estimated factor scores.